Getting Started
Warning
In active development. Currently pre-alpha -- API may change significantly in future releases.
Import the mdai library
Create an mdai client
The mdai client requires an access token, which authenticates you as the user. To create a new token or select an existing token, navigate to the Personal Access Tokens tab in the user settings page found on the top right of the project page on your MD.ai domain (e.g., public.md.ai).
Example output:
Note
Keep your access tokens safe. Do not ever share your tokens.
Define a project
Define a project you have access to by passing in the project id. The project id can be found in the URL in the following format: https://public.md.ai/annotator/project/{project_id}.
For example, project_id would be LxR6zdR2 for https://public.md.ai/annotator/project/LxR6zdR2. Specify optional path as the data directory (if left blank, will default to current working directory).
A project object will attempt to download the dataset (images and annotations separately) and extract images, annotations to the specified path. However, if the latest version of images or annotations have been downloaded and extracted, then cached data is used.
Here are the various arguments that you can choose from while trying to define and download objects from a project -
p = mdai_client.project(
project_id,
dataset_id=None,
label_group_id=None,
path=".",
force_download=False,
annotations_only=False,
extract_images=True,
):
"""
Arguments:
project_id: hash ID of project (required)
dataset_id: hash ID of dataset to use (optional - default `None`)
label_group_id: hash ID of the label group to scope to (optional - default `None`)
path: directory used for data (optional - default `"."`)
force_download: if `True`, ignores possible existing data in `path` (optional - default `False`)
annotations_only: if `True`, downloads annotations only (optional - default `False`)
extract_images: if 'True', automatically extracts downloaded zip files for image exports (optional - default 'True')
"""
The exported data may also be scoped by individual datasets by specifying dataset_id. By default, all datasets within the project will be included.
Examples:
Using default arguments will download both images and annotations from all datasets and across all label groups -
Output:
Using path './lesson3-data' for data.
Preparing annotations export for project LxR6zdR2...
Preparing images export for project LxR6zdR2...
Using cached images data for project LxR6zdR2.
Using cached annotations data for project LxR6zdR2.
Note
If you are unable to export images from within the Annotator, this feature maybe turned off in the project by your institution/company or you might not have access based on your role in the project. Contact your project admin for more details.
Create project locally with images and annotations from MD.ai
To use the MD.ai API using locally available images you need to do two things -
- Images need to be in a specific format.
Projectrequires the images to be inStudyInstanceUID/SeriesInstanceUID/SOPInstanceUID.dcmformat. - Download the annotations and create the project:
PATH_TO_IMAGES = 'path to my data goes here'
PROJECT_ID = 'get the project id from the Annotator'
mdai_client.project(PROJECT_ID, path=PATH_TO_IMAGES, annotations_only=True)
This downloads the json only. Grab the name of the json file and create the project with:
Note
The images in PATH_TO_IMAGES need to be in a specific format to work with the rest of the api. Convert your images to StudyInstanceUID/SeriesInstanceUID/SOPInstanceUID.dcm format first.
Prepare data
Show available label groups
Set label ids and corresponding class id
Label ids and corresponding class ids, must be explicitly set by Project.set_label_dict() method in order to prepare datasets.
Example:
# this maps label ids to class ids
labels_dict = {
'L_ylR0L8': 0, # background
'L_DlqEAl': 1, # lung opacity
}
p.set_labels_dict(labels_dict)
Show available datasets
Get dataset by id or by name
dataset = p.get_dataset_by_id('D_ao3XWQ')
dataset.prepare()
dataset = p.get_dataset_by_name('Train')
dataset.prepare()
Show label ids, class id and class name
Example output:
Label id: L_ylR0L8, Class id: 0, Class text: No Lung Opacity
Label id: L_DlqEAl, Class id: 1, Class text: Lung Opacity
Split data into traing and validation datasets
By default, dataset is shuffled, and the train/validation split ratio is 0.9 to 0.1.
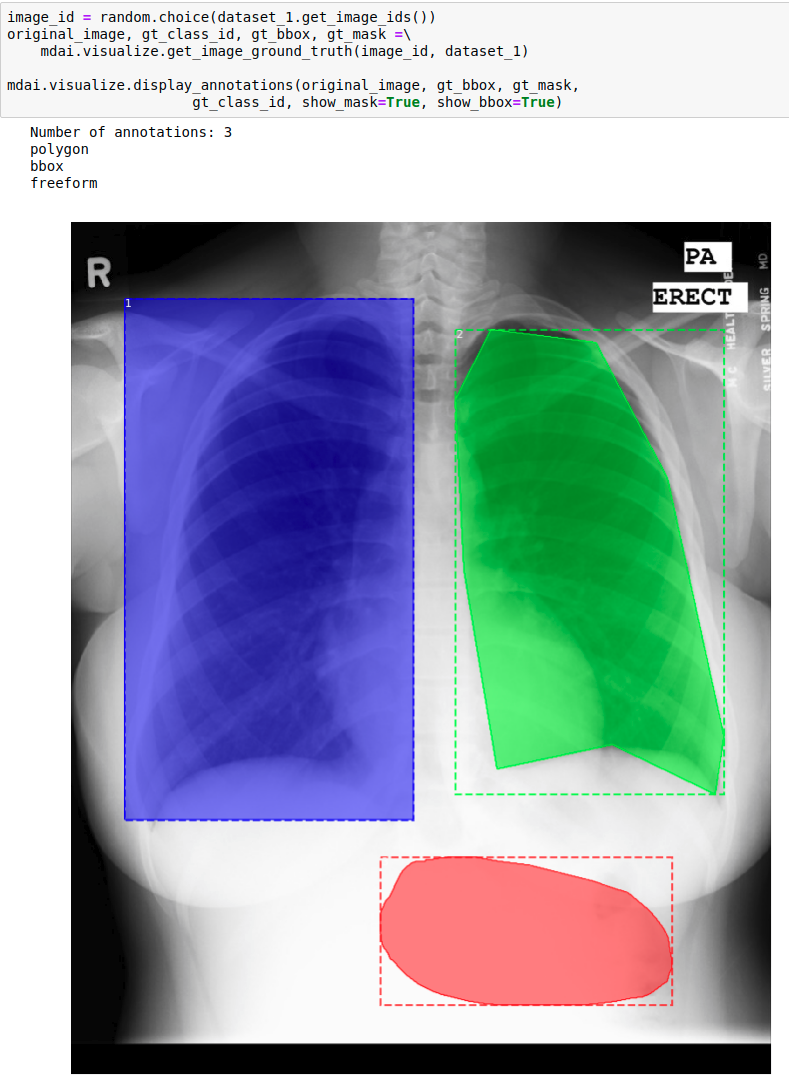
Visualization
Visualization of different annotation modes
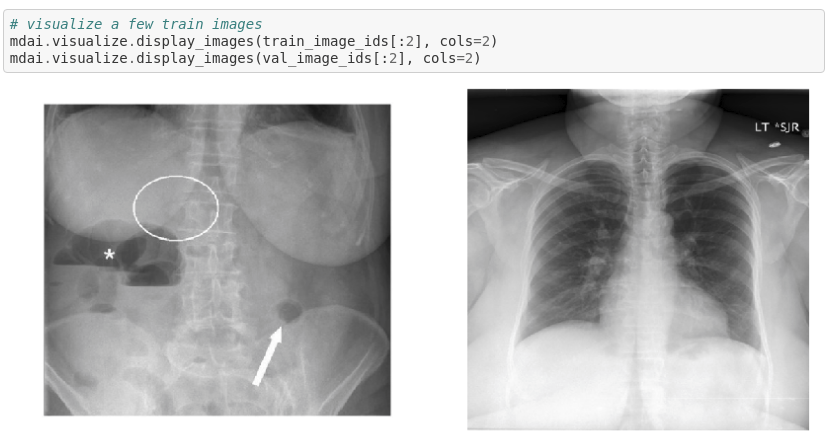
Display images