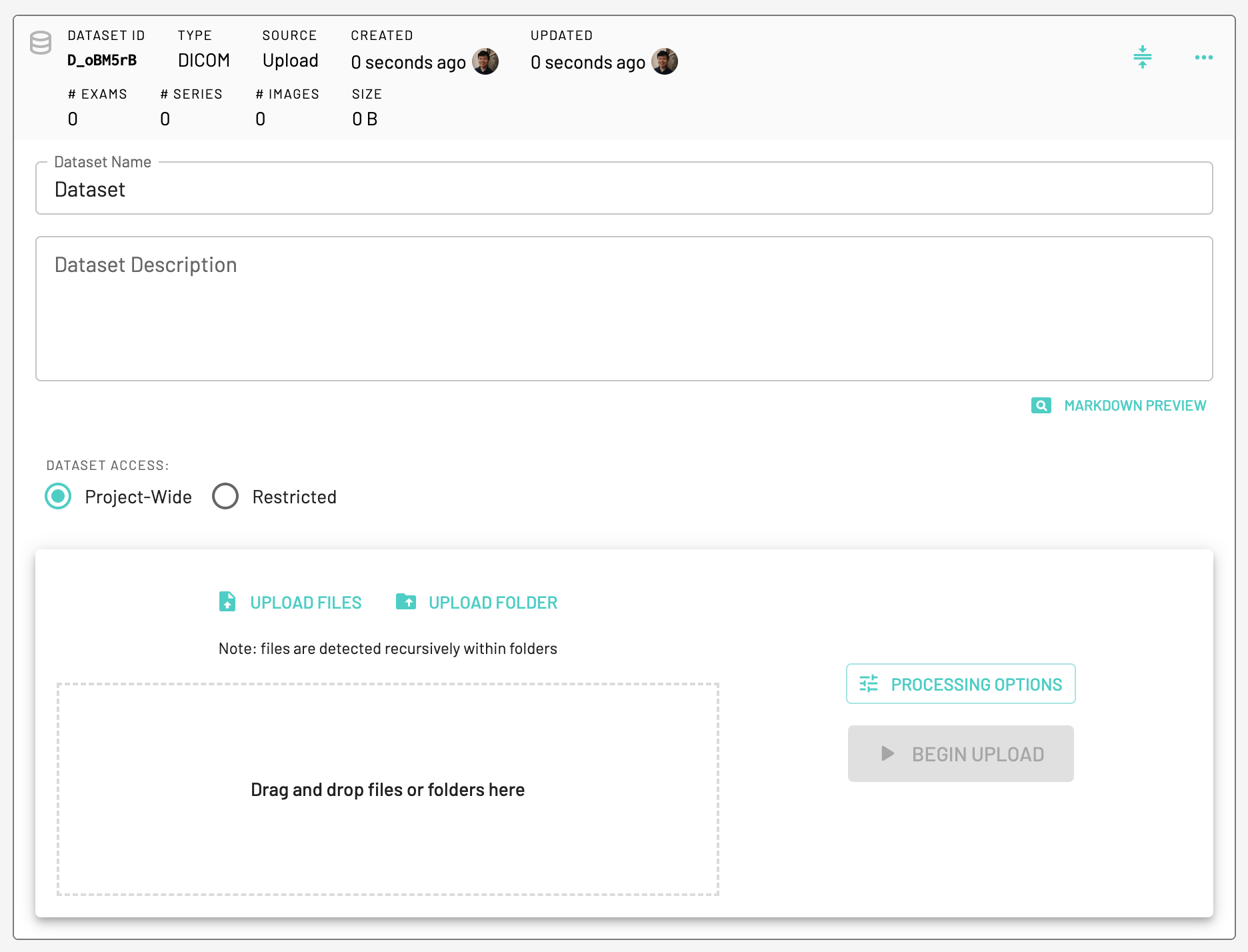
Create Dataset
Every project should contain at least one dataset. A common use case for having more than one dataset in a project is separating training and test sets. After creating a new project, click on the New Dataset button to create a new dataset. This dataset will serve as the container into which your data will be loaded. Note the project and dataset IDs.
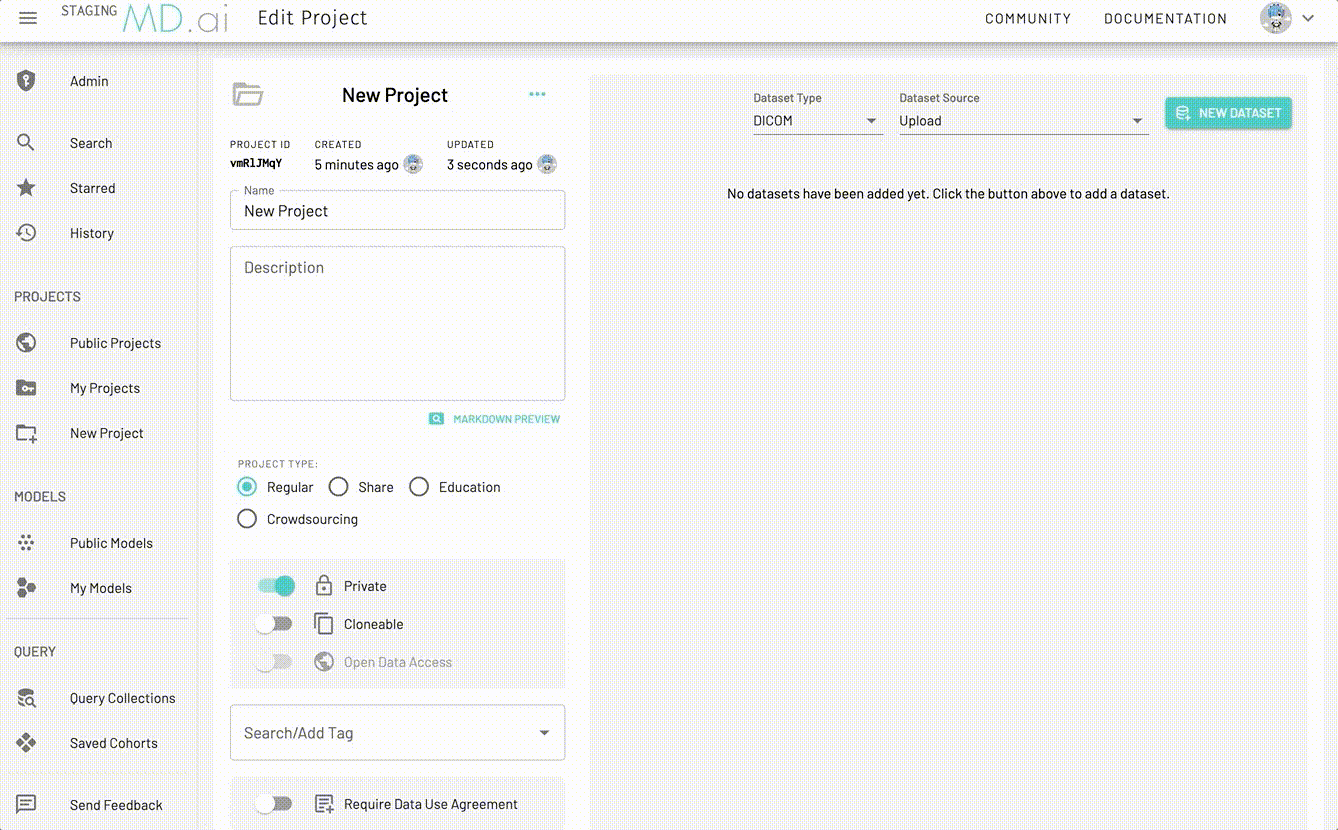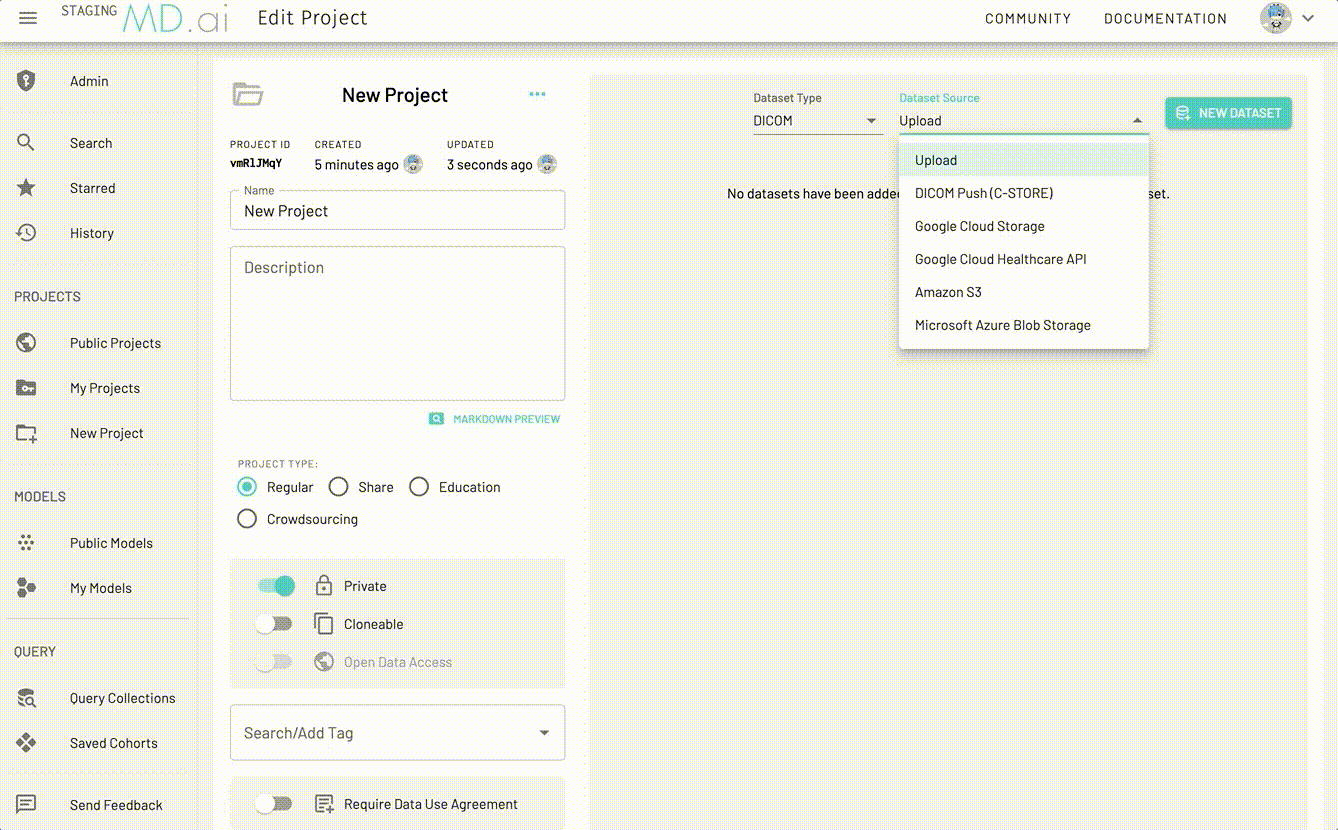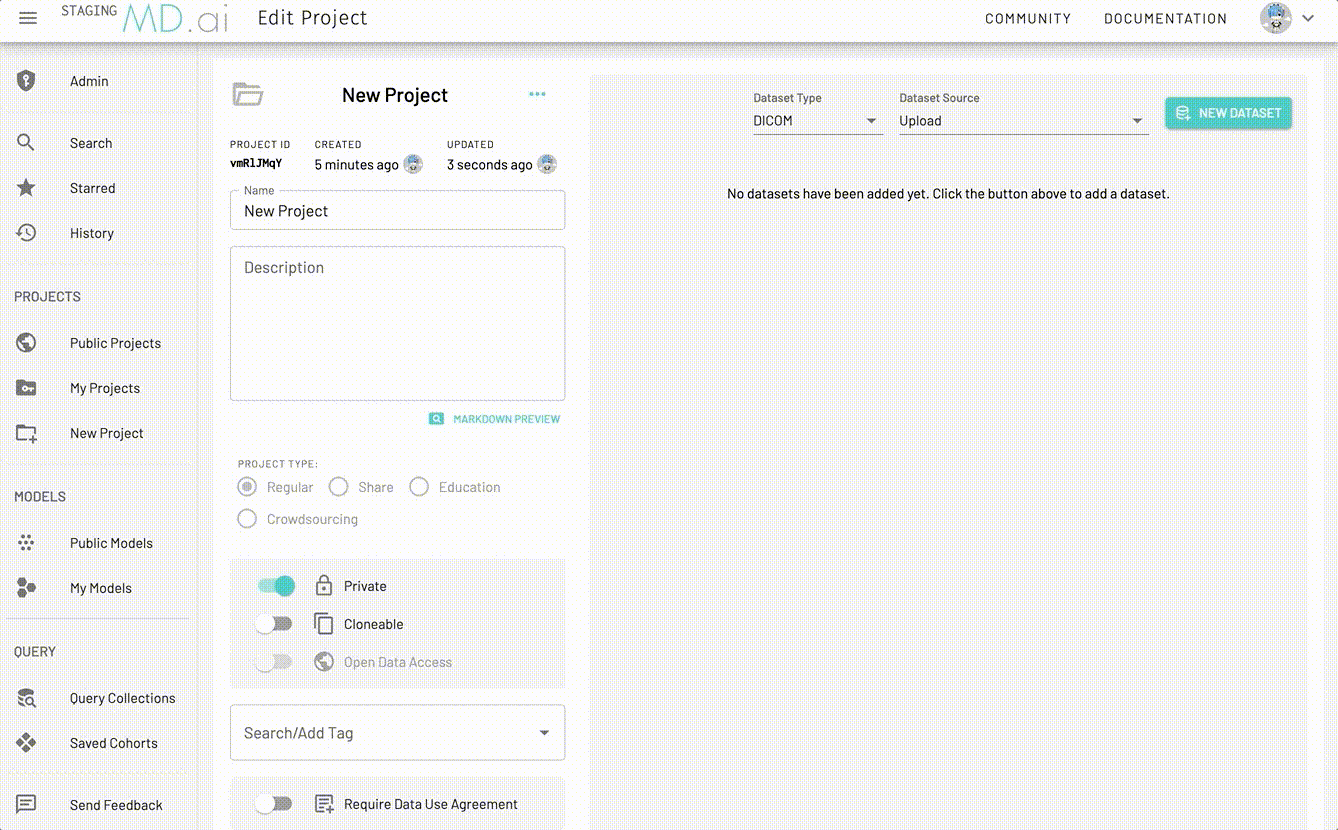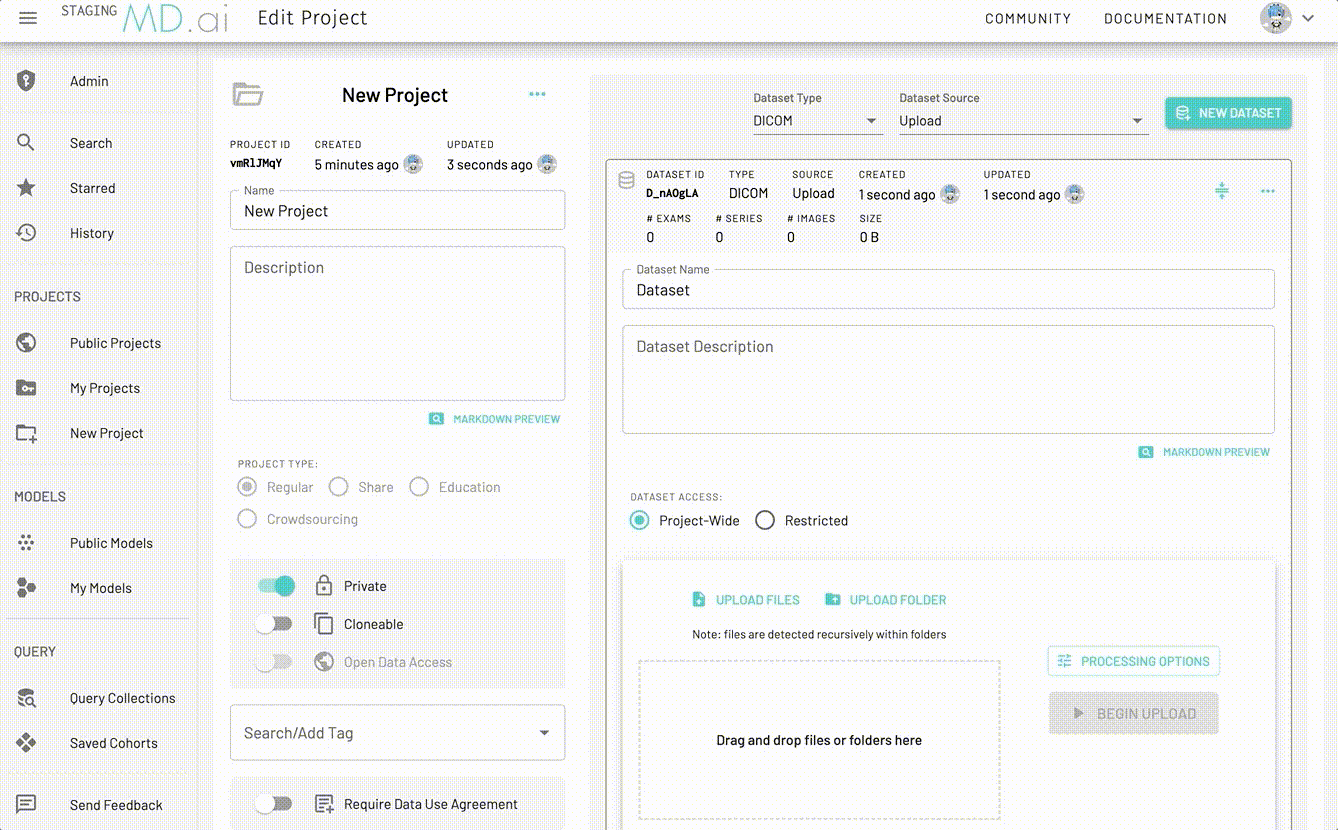
For each dataset you can also choose to either keep the Dataset access Project-Wide or Restricted.
We currently supporte DICOM, JPEG, PNG and BMP images along with MP4 and H264 videos to be displayed and annotated on our viewer. Learn more about annotating videos here.
Supported Medical Modalities
- CR: Computed Radiography
- CT: Computed Tomography
- DX: Digital Radiography
- IVOCT: Intravascular Optical Coherence Tomography
- MG: Mammography
- MR: Magnetic Resonance Imaging (MRI)
- NM: Nuclear Medicine
- OCT: Optical coherence tomography (non-Ophthalmic)
- OPT: Ophthalmic Tomography
- OT: Other
- PT: Positron emission tomography
- RF: Radio Fluoroscopy
- RG: Radiographic imaging (conventional film/screen)
- US: Ultrasound
- XA: X-Ray Angiography
Load external data to a dataset
Choose a dataset type eg. DICOM. There are multiple ways (Dataset Sources) to add external data to your project's dataset:
- Upload
- DICOM Push (C-STORE)
- Google Cloud Storage
- Google Healthcare API
- Amazon S3
- Microsoft Azure Blob Storage
Note
In addition to these methods for creating new datasets using external data, you can also create new datasets from subsets of already existing exams/series/images in your dataset after applying label filters. Read more about it here
Preprocessing Options
For all dataset types, we support additional preprocessing options such as ignoring secondary captures, setting a filename preset and defining a default ordering of the exams either using Patient ID, Study Date/Time, Study Description or Random.
Ignore Secondary captures
For every new dataset, you can choose to ignore secondary captures so that they are not uploaded to MD.ai for viewing. This can be useful for de-identification purposes if there is a concern for burned-in PHI data.
